Optuna:超参优化框架
概述
Optuna (KDD19) 是一个超参搜索工具,通过在代码中定义超参空间,然后执行一定次数的实验寻找最优组合。
搜索过程的实验数据会保存到数据库里(如sqlite),支持并行调参,支持数据可视化。
相关内容
目前在比较多的科研代码中可见到一些实验数据管理工具,如CometML、Wandb和Neptune。
这些工具可在代码中上传实验数据到云,并在云端对提供实验数据管理、可视化和协作等功能,也提供超参搜索功能。
Optuna强在超参搜索,弱在数据管理、可视化,不上云所以没有协作,因此也有将Optuna和Wandb搭配使用的。
类似超参优化框架还有Hyperopt等,Github上Optuna星多所以学习Optuna。
超参优化方法
1. 人工调参(manual tuning)
2. 网格搜索(grid search)
for alpha in 0.3 0.5 0.7; do
for beta in 0 0.1 0.5 0.9; do
python3 main.py --alpha $alpha --beta $beta | tee -a main.log
done
done
好写脚本,顺便做了ablation study。
3. 随机搜索(random search)
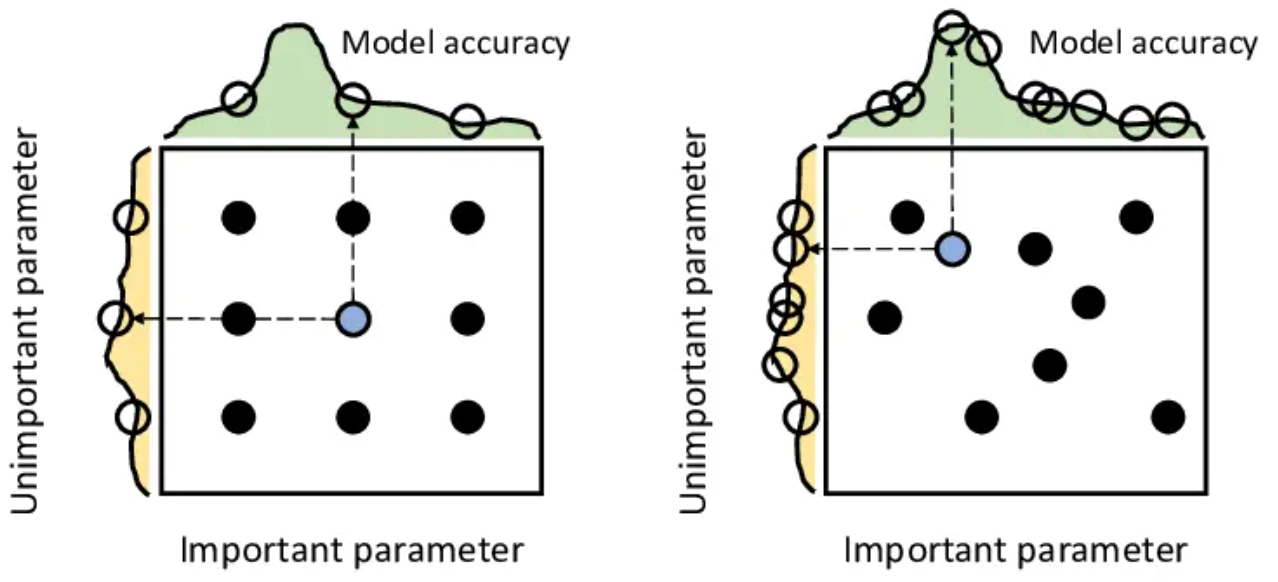
比grid search覆盖空间更广(同一超参在每个trial中值都不一样)
4. 贝叶斯优化(Bayesian Optimization, NIPS11)
对历史数据建模(常用GPR或TPE),兼顾好优化(Exploitation)和大方差(Exploration)。
CometML这些都提供贝叶斯优化帮助调参。
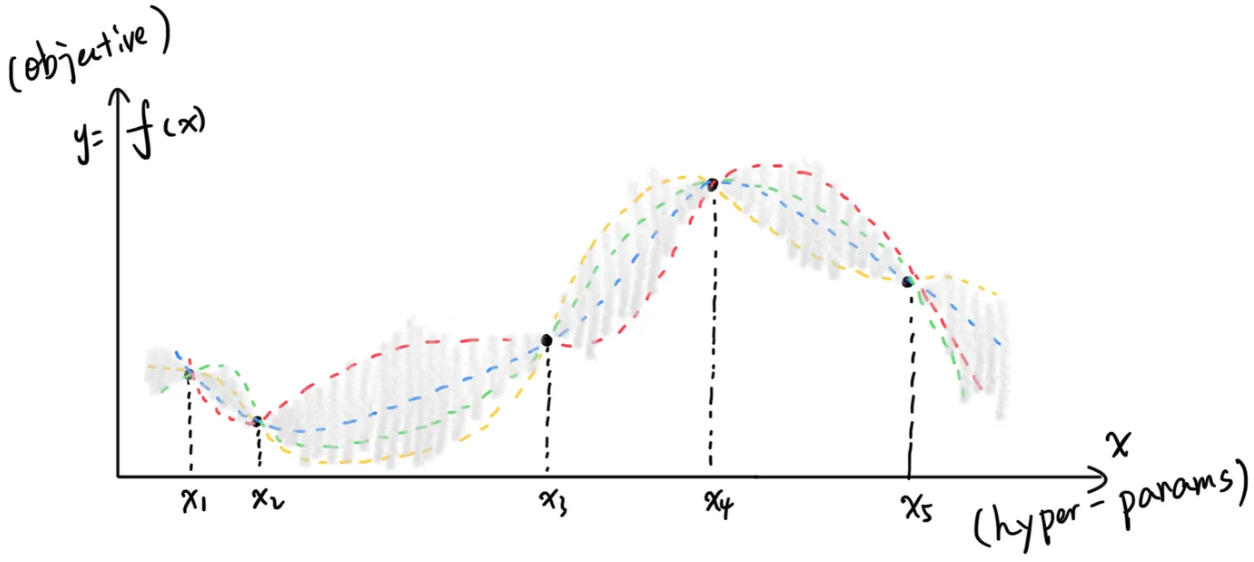
Optuna
提供三大功能:
- 通过Sampler(默认用TPE)根据历史测试结果做贝叶斯优化,减少测试数
- 通过Pruner根据测试中间结果指导早停,缩短测试时间
- 通过Optuna Dashboard对调参过程可视化
基本用法:调参
在脚本中定义本次study,其中objective是每次测试都调用获取优化指标的函数。
# 只要study_name和storage一样,就可以多个脚本一起并行调参
study = optuna.create_study(study_name='test1', storage='sqlite:///xx.db', load_if_exists=True)
# 可以存储自定义数据
study.set_user_attr('contributors', ['Yi', 'Luo'])
# 也可以先跑n_trials次测试,视情况重复运行脚本、接着再跑n_trials次
study.optimize(objective, direction='minimize', n_trials=3)
一个study中每次测试都叫一个trial。
通过trial获取本次测试超参的值,进行测试,然后返回优化指标。
def objective(trial):
# 常用3种限定超参的方法,其它的也都可以用这三种表示
dist = trial.suggest_categorical('dist', [1, False, 'opt'])
# step是步长,在suggest_float中也可以用
epochs = trial.suggest_int('epoch', low=100, high=200, step=10)
# log指在对数域采样
lr = trial.suggest_float('lr', low=0.0001, high=0.1, log=True)
# 每个trial可以存储自定义数据
trial.set_user_attr('acc', 0.98)
# 自定义数据可以调用
print(trial.study.user_attr('contributors'))
# 如果自己本来的脚本不好搭配optuna,可以写成子进程
p = subprocess.Popen(
'python3 main.py --dist %s --epochs %d --lr %.3f' % (dist, epochs, lr),
shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
# 这种方法需要从标准输出中解析出指标(如果报告中间值还可以激活pruning)
while 1:
lines = p.stdout.readlines()
for line in lines:
line = line.strip().decode()
if line.startswith('score: '):
acc = float(line.split('score: ', 1)[1])
if (not lines) and type(p.poll()) == int:
break
# 需要返回一个评估指标,多个也支持,外面direction换成directions(列表)
return accuracy
Optuna可以依据历史trials信息基于贝叶斯优化高效地选择超参,在我试用时相比Grid Search能减少90%以上的trial数。
进阶用法:Ablation Study
由于Study在创建后,suggest_categorical等超参设置便不能再改,而调参轨迹可能无法覆盖ablation study的各种情况(即使覆盖也有数据点不均衡的问题),因此无法保障在调参的同时能利用数据点做完ablation study。
此时可利用study.enqueue_trial接口预约一定数量的测试,这些测试使用指定的超参。如
# 先随便调20次,累积一些测试信息
study.optimize(objective, n_trials=20)
# 每类情况调10次
for _ in range(10):
# 第一类情况
study.enqueue_trial({'use_feature_1': True})
# enqueue_trial只是“预约”,所以下面要将预约执行
study.optimize(objective, n_trials=1)
# 另一类情况
study.enqueue_trial({'use_feature_2': False})
study.optimize(objective, n_trials=1)
用法2:早停
在减少trial数之外,Optuna还提供一些Pruner算法,以提前结束预期效果不好的trial(需要在脚本过程中报告中间值,如每个epoch或run的结果),进一步节省调参时间。
以下两个Pruner在深度学习中比较有用:
1. SuccessiveHalvingPruner
每个trial都是一次完整的模型训练(我们通常称为run),根据每个epoch的效果决定该run是否早停。
SuccessiveHalvingPruner在不同epoch处设置有“关卡”,每个关卡只放一定比例的trial过去,其它的停掉。
以默认参数为例,第一个trial不停,以此测算出max_epoch如1000,进而设置minimal_resource为1%即10,默认的通过比例为1/4,所以关卡设置在第10、40、160、640 epoch处。
类似效果的还有MedianPruner(停掉表现在中位数以下的,没那么复杂的关卡设置)等等。
2. WilcoxonPruner
每个trial包含k个run(如k折验证),根据已知runs的效果提前结束最终平均效果可能较差的trial。
用法3:可视化
需要python3 -m pip install optuna-dashboard,然后optuna-dashboard --storage sqlite:///xx.db就可以运行一个前端服务,查看实验状态、每个实验的数据、各个参数的重要性等等。
另外还有个纯前端页面,将sqlite数据库丢上去就可以可视化,但功能比本地服务少。
Page Not Found
Try to search through the entire repo.